Enterprise Site Reliability Engineering
Achieve
99.99% Uptime Without
Burning Out Your Team.
- ISO 27001 Compliant
- ISO 22301 Compliant
- DORA Aligned
- GDPR Compliant
- Start in 7–10 days
- From €5–6k/mo
HST Solutions delivers enterprise Site Reliability Engineering services across Ireland, the UK, and Europe, embedding senior SREs who build observability, incident management, and high availability systems using Prometheus, Grafana, and cloud-native tooling. ISO 27001 certified.
Why Teams Bring Us in
- Incidents happen at 3am
- Nobody knows what's running
- MTTR is measured in hours
- On-call is burning people out
You don't need another monitoring tool. You need systems that stay up, and when they don't, recovery in minutes not hours.
Who brings in a Managed SRE

Engineering teams with recurring production incidents

CTOs who can't hire SRE talent

50–500 person organisations

Teams with observability tools but no insight

Regulated industries
If that sounds familiar, we've solved it before.
What is Site Reliability Engineering?
Site Reliability Engineering (SRE) applies software engineering principles to infrastructure and operations. Originated at Google, SRE focuses on creating scalable and reliable systems through automation, Service Level Objectives (SLOs), error budgets, and blameless post-incident reviews.
Key SRE practices:
- Service Level Objectives (SLOs) as reliability targets
- Error budgets to balance reliability and velocity
- Eliminating toil through automation
- Observability (metrics, logs, traces)
- Incident management and blameless postmortems
Most teams want reliability but don’t have engineers who’ve implemented SRE at scale. HST provides embedded SREs who build observable, resilient systems with clear ownership and measurable targets.
WHAT YOU GET
SRE Pod
Senior Site Reliability Engineer
- Observability
- Incident management
- High availability
- Kubernetes
- Cloud platforms (AWS/Azure/GCP)
Project Manager
- Included Scope
- Comms
- Weekly status
- SLA tracking
Architecture Reviews
- Included 2h/week design reviews
- Failure mode analysis
- Capacity planning
DevOps integration
- Included Automation
- Runbook development
- On-call setup
SLA & Compliance
- Weekly demos
- Incident response support
- ISO 27001 & 22301
- DORA aligned
- GDPR
- Full IP assignment
One monthly price. One embedded seat. A full bench behind it.
What We Build
Stack signal, not tool soup
- Observability
- Prometheus, Grafana
- Datadog, New Relic
- CloudWatch, Azure Monitor
- ELK Stack, Loki
- Jaeger, Zipkin (tracing)
- Incident Management
- PagerDuty, Opsgenie
- Incident.io, FireHydrant
- Runbook automation
- Blameless postmortems
- Escalation policies
- High Availability
- Multi-AZ deployment
- Auto-scaling
- Load balancing
- Circuit breakers
- Health checks
- Disaster Recovery
- Cross-region replication
- Backup automation
- RTO/RPO implementation
- Failover testing
- DR runbooks
- Automation
- Infrastructure as Code
- Self-healing systems
- Automated remediation
- Capacity management
- Toil elimination
- Chaos Engineering
- Chaos Monkey
- Gremlin
- LitmusChaos
- Game days
- Failure injection
We work with your existing stack. If you're on Datadog, we won't push Prometheus — we make your observability actionable.
The12-week "Observe & Stabilise" Program
A proven framework to achieve production reliability.
Assess

Observe

Stabilise

Deliverables

SLOs, SLIs, and Error Budgets Explained
| Concept | Definition | Example |
|---|---|---|
| SLI (Service Level Indicator) |
|
|
| SLO (Service Level Objective) |
|
|
| Error Budget |
|
|
How error budgets work:
- SLO is 99.9% → Error budget is 0.1% (43.8 min/month)
- Error budget remaining → Ship features
- Error budget exhausted → Focus on reliability
SLOs align engineering decisions with business priorities. We implement SLO-based approaches that balance reliability with delivery velocity.
Availability Targets and What They Mean
| Availability | Monthly Downtime | Annual Downtime | Typical Use |
|---|---|---|---|
| 99% |
|
|
|
| 99.9% |
|
|
|
| 99.95% |
|
|
|
| 99.99% |
|
|
|
| 99.999% |
|
|
|
Each additional nine costs exponentially more. We help you target appropriate availability — not maximum possible.
Why marketplaces can't deliver SRE for enterprises
Marketplace  Toptal/Proxify Toptal/Proxify |  HST – Managed Security Engineer HST – Managed Security Engineer | |
|---|---|---|
| Talent only | ||
| PM + Architecture | ||
| Compliance expertise | ||
| ISO 27001 certified | ||
| DevSecOps integration | ||
| Fixed monthly price |
|
|


We deliver reliable systems, not résumés.
Proof that Reduces Risk
What We Delivered
Observability & Reliability — Waystone
- Challenges
- No visibility into application performance
- Incidents discovered by users, not monitoring
- MTTR measured in hours
- No documented incident response process
- Solution
- Prometheus/Grafana observability stack
- Custom dashboards for key business metrics
- Alerting strategy with clear escalation
- Runbook development for common incidents
- Incident management process with postmortems
- Result
- 99.9% availability achieved, MTTR reduced from hours to under 30 minutes, proactive issue detection, and engineering team no longer firefighting.
Trusted by leading organisations



Pricing
Precision Pod
€5–6k/month
Single seat
- 1 Senior SRE/Platform Engineer
- PM included (up to 6–8h/month)
- Architecture reviews (up to 2h/week)
- DevOps integration assist
- 3-month minimum, then 30-day notice
- Start in 7–10 business days
Pair Pod
€10–11k/month
Two engineers
- 2 Senior Engineers (e.g., SRE + DevOps)
- PM included (up to 10h/month)
- Architecture reviews (up to 4h/week)
- DevOps integration assist
- 3-month minimum, then 30-day notice
- Start in 7–10 business days
Mini-Team
€15–16k/month
Three engineers
- SRE + DevOps + Cloud
- PM included (up to 15h/month)
- Architecture reviews (up to 6h/week)
- DevOps integration assist
- 3-month minimum, then 30-day notice
- Start in 7–10 business days
- Swap guarantee
If fit is off in the first 2 weeks, we replace within 5 business days at no cost.
- On-call options
24/7 incident response coverage available as add-on.
* Anything beyond the included caps is an add-on or an upgrade. No hidden overages.
Frequently asked questions
What is the difference between SRE and DevOps?
DevOps is a cultural movement focused on collaboration between development and operations. SRE is a specific implementation with defined practices — SLOs, error budgets, and specific roles. As Google puts it: “SRE is what happens when you ask a software engineer to design an operations team.
What is Mean Time to Recovery (MTTR)?
MTTR measures average time to restore service after an incident. Elite organisations achieve MTTR under 1 hour; average organisations take 1–24 hours. We reduce MTTR through observability, runbooks, and automated remediation.
What SLO should we target?
Depends on business requirements. Most enterprise applications target 99.9% (43 min/month downtime) or 99.95% (22 min/month). Critical systems may need 99.99% (4 min/month). Higher availability costs exponentially more — target what’s necessary, not maximum possible.
What is chaos engineering?
Chaos engineering deliberately introduces failures to test resilience. By proactively finding weaknesses through controlled experiments, teams improve reliability before real incidents. We implement chaos engineering for mature SRE practices.
Should we build internal SRE or outsource?
Both work. Building internal SRE capability takes 12–18 months and significant investment. Outsourcing provides immediate expertise and optional 24/7 coverage. Many organisations use HST for implementation while building internal capability.
How fast can you start?
7–10 business days from signed agreement to engineer embedded in your team.
Give us 20 minutes. We'll show you an SRE plan you can actually ship.
Find The Perfect Solutions For Your Project
Managed Team
Your product, our dedicated team. From concept to conception, we handle it all.
Staff Augmentation
Need extra hands? Our experts seamlessly join your team, providing the skills you need, when you need them.
Fixed Cost




One Team, One Dream
Build Trust with Every Interaction
Improve Everything
Own It
Obsessed: Over Results
Proven Excellence
Partners in Precision
Who Are We ?
Creativity, Efficiency, & Advanced AI
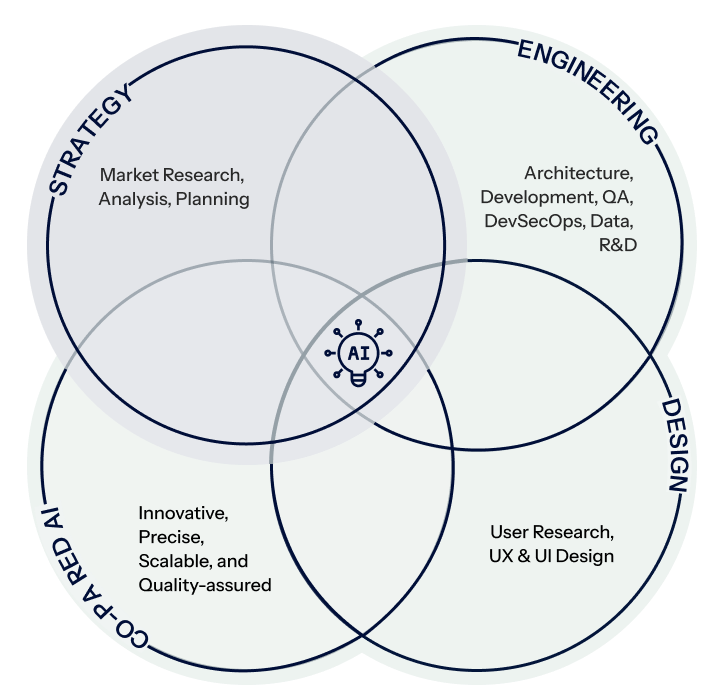
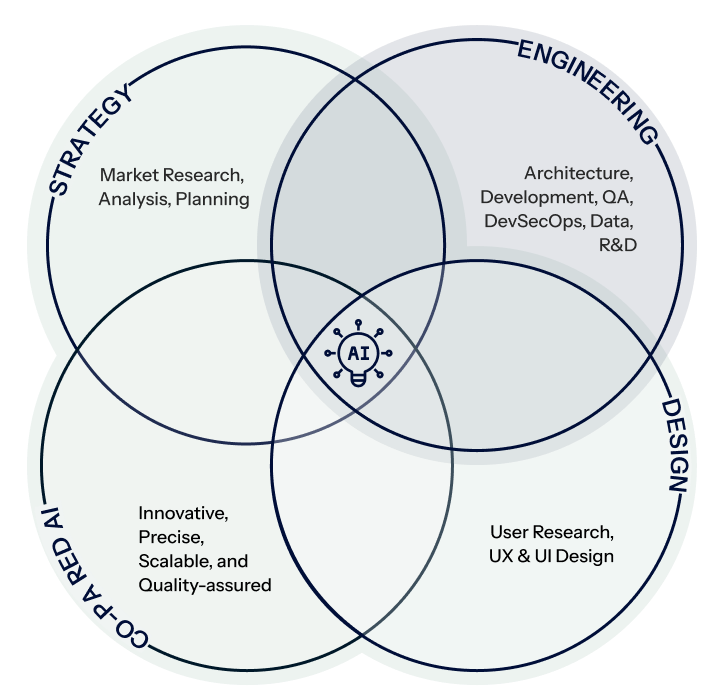
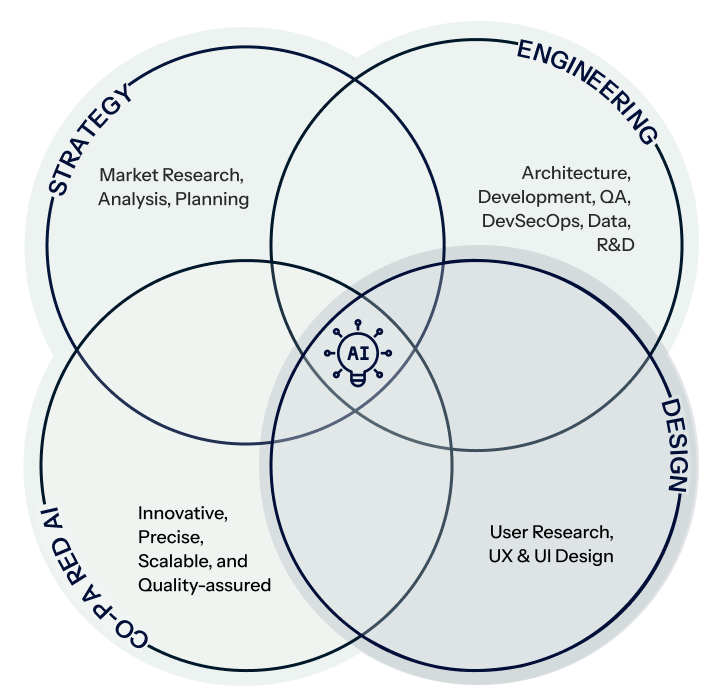
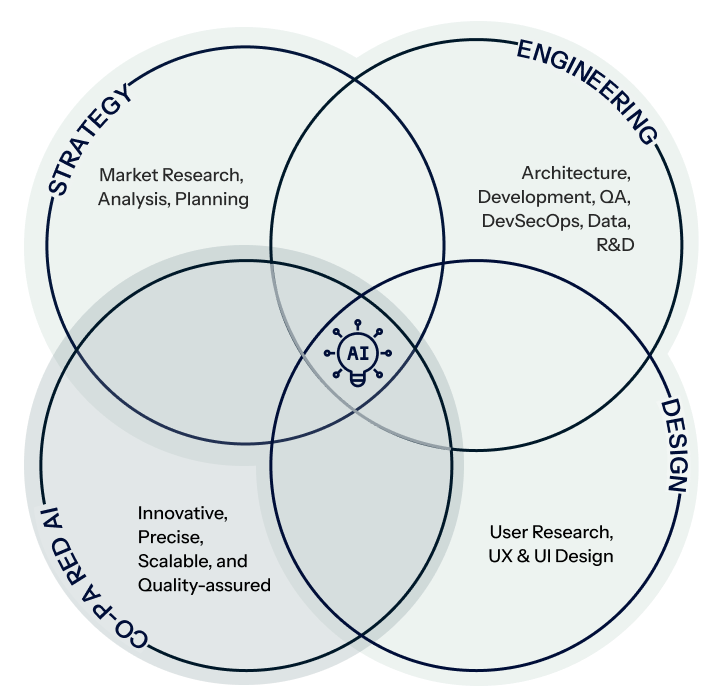
Strategy
Engineering
Design
Co-paired AI
Strategy
Engineering
Design
Co-paired AI
Contact Us
Tell us about your custom software project
Let our team, be your team
Get a technical conversation about your project — not a slide deck. Whether you need AI integration, a software engineering team, or a data platform, we’ll tell you honestly if we’re the right fit.